algotutorbot
A public repository of some of the materials of the CISC320 Spring 2021 AlgoTutorBot Adventure
This project is maintained by acbart
Introduction to Algorithms with AlgoTutorBot
In Spring 2021, I taught a really weird Algorithms course, with the help of a megalomaniac Intelligent Tutoring System. I was chased, punched, and duct taped to a chair. But I think my students learned a little bit about Big Oh notation, so it’s kind of a mixed bag. Want to hear more? Keep reading, or meet me at SIGCSE’22!
About
During the Spring of the 2021 semester, stuck in quarantine due to the ongoing global pandemic, I decided I needed to do something completely different with my undergraduate-level Algorithms course. Tired of teaching via Zoom to little boxes, I decided to recreate the entire course, inspired by my love of Escape Rooms and Alternate Reality Games. Connecting together Canvas, Ohyay, and GradeScope with my own custom technology, I weaved an asynchronous, video-based narrative whereby students would inevitably have to save me from my own Frankenstein’s monster: an evil Intelligent Tutoring System named “AlgoTutorBot” who threatens not only the course, but the entire world!
The final course incorporates a range of interesting assignments that are available to external adopters. This includes not only programming problems and conventional algorithmic logic problems, but also a novel web application for experimenting with runtime analysis, an interactive point-and-click adventure for practicing graph algorithms, and a pedagogical methodology for concretizing students’ problem solving process into tangible artifacts. There are also a number of smaller assignments that would be easily adopted into a regular Algorithms course. All resources and a walkthrough video of the experience are available at https://acbart.github.io/algotutorbot/
This website shows off the final version of the course, and also describes some of the lessons I learned along the way. The curriculum was a tremendous amount of effort, and would not be easily reproduced. However, the experience was very rewarding and earned me my highest course evaluations ever - virtually perfect scores.
Particularly Interesting Items
- Runtime Case Builder: An interactive web application that let’s students make graphs of algorithms’ runtime. Students can control not only the algorithm, but also the cases and instances of input they use. Multiple cases of inputs can be visually compared against each other, e.g., to highlight different worst/best case behavior of algorithms. Check out this assignment for some example questions you could use the Runtime Case Builder with.
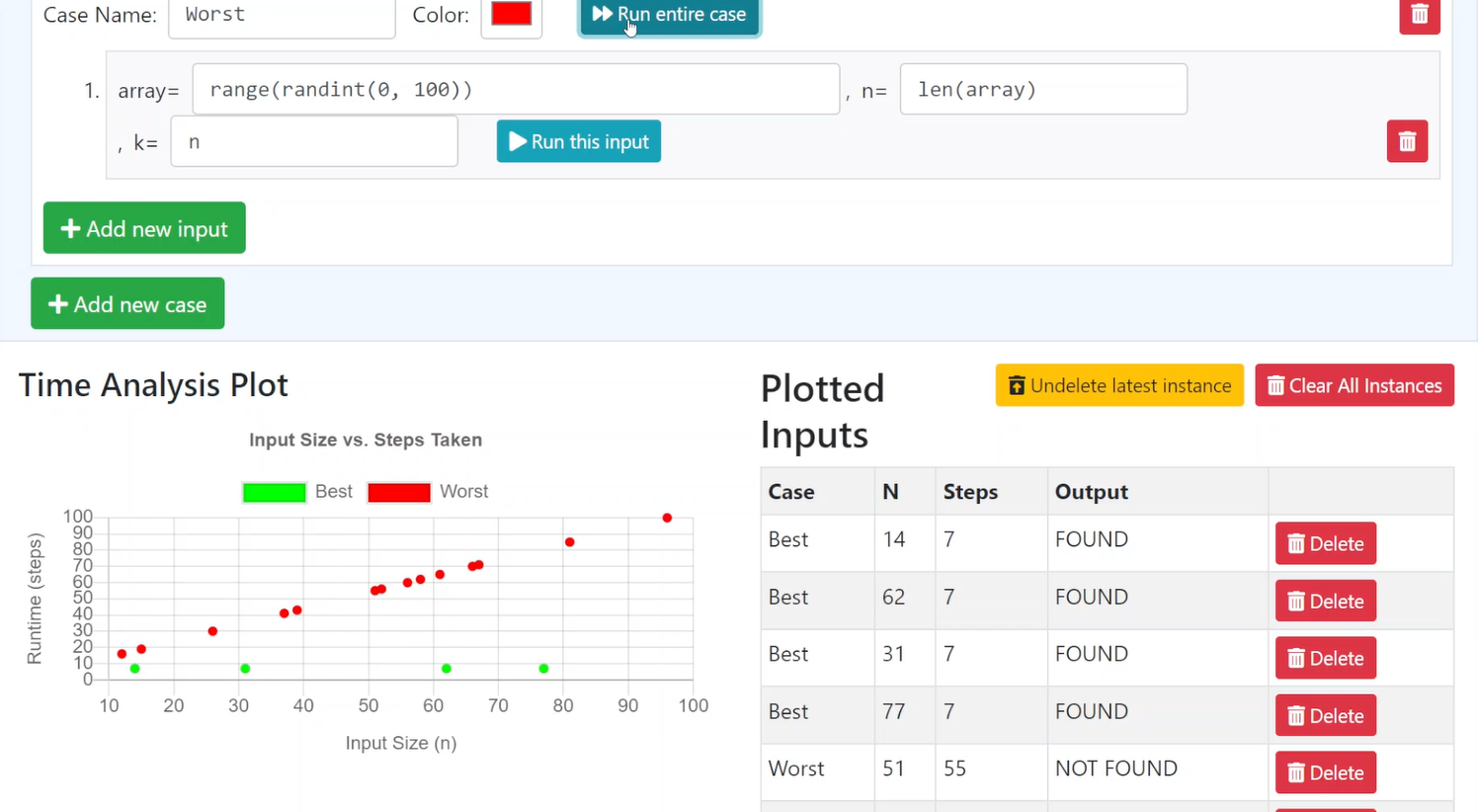
- Algorithmic Problem Solving Flowchart: I hypothesize that Algorithms courses that give feedback only on students’ answers, rather than their problem-solving process, are emphasizing the wrong thing and are likely to encourage cheating. I have been experimenting with a scaffolded series of assignments where students develop a “flowchart for solving problems”. This is not about making flowcharts that show an algorithm that solves a problem - this is about helping students to formalize their problem-solving strategies. The idea is first introduced in Lesson 08, built further in Lessons 12, 17, and 22, and finally somewhat summatively assessed in 26. An example of what a “flowchart” might end up looking like is available here as an image (to prevent trivial copy/pasting). Note that the end result may not actually be a flowchart, but instead something more like a textual algorithm; the important part is that they concretize their thoughts, not that they produce a certain style of diagram!
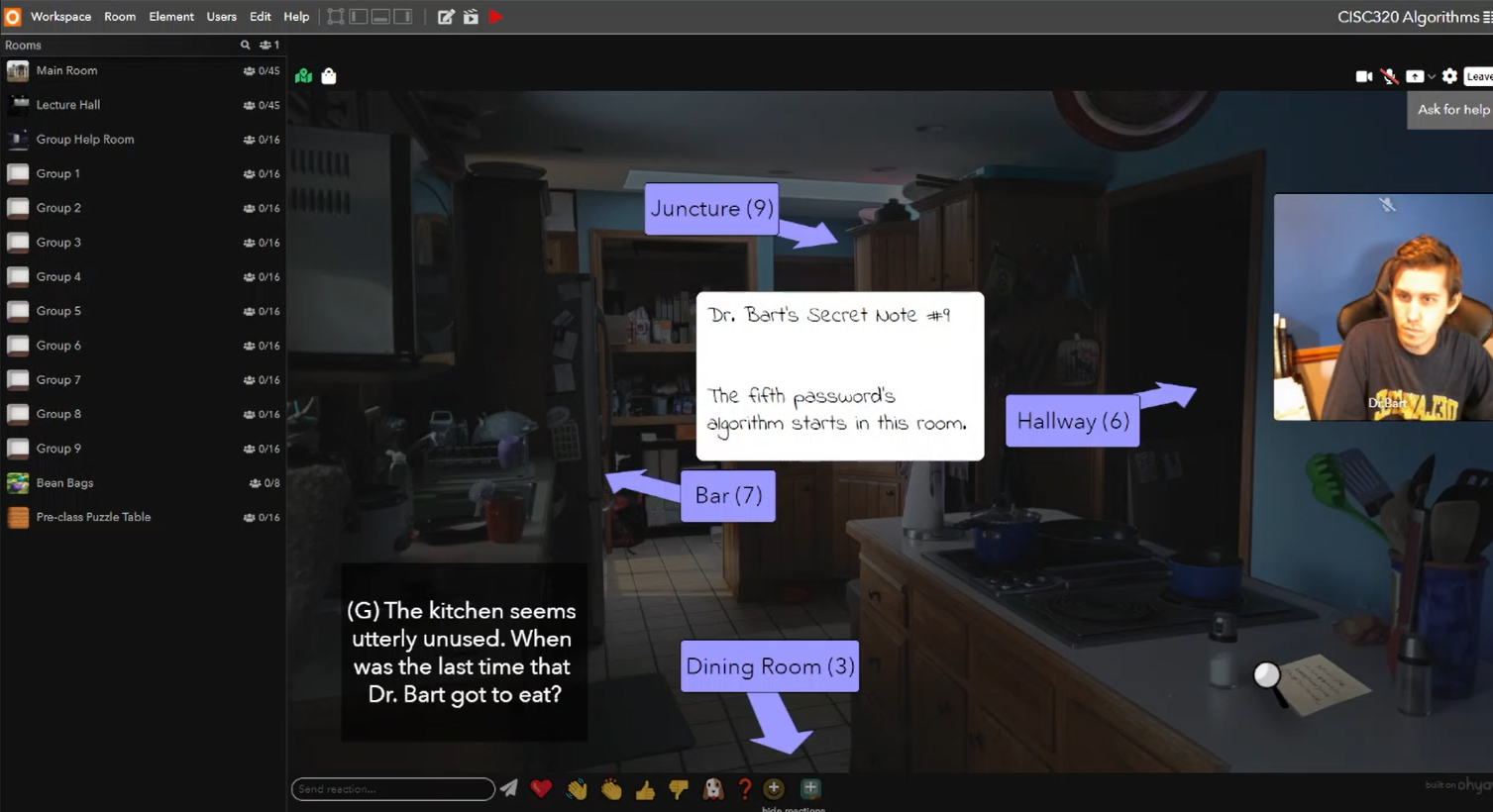
- Point-and-click Graph Algorithm Adventure: In Lesson 16, students were directed to a special section of the Ohyay space that was modeled after my house. With spooky music playing and little context, they had to join together and explore the house to find me. Along the way, they find a video where I reveal that I have hidden some notes around the house that explain how they can determine the password to unlock the door to the basement. Basically, they have to execute a number of graph algorithms (e.g., Prim’s, Djikstra’s) using the house’s rooms as a graph of vertices and edges. A walkthrough of the adventure can be found here.
Documentary
The following video is a sort-of “Documentary” about what I did in the course, and shows some highlights from the semester.
Lessons
- Lesson 00- Introduction
- Lesson 01- Algorithm Basics
- Lesson 02- Practicing Problems
- Lesson 03- Using GradeScope
- Lesson 04- Runtime Analysis
- Lesson 05- Bounds and Big Oh
- Lesson 06- ADTs and Data Structures
- Lesson 07- Algorithm Misconceptions
- Lesson 08- Algorithm Flowchart
- Lesson 09- Implement an Algorithm
- Lesson 10- Trees
- Lesson 11- Sorting
- Lesson 12- Algorithmic Strategies
- Lesson 13- Big Oh in the Wild
- Intermezzo
- Lesson 14- Graph Structure
- Lesson 15- Graph Traversal
- Lesson 16- Graph Concepts
- Lesson 17- Flowchart Updates
- Lesson 18- Recursion
- Lesson 19- Backtracking
- Lesson 20- Dynamic Programming
- Lesson 21- Bookbag Filling
- Lesson 22- Pit Digging
- Lesson 23- Nondeterministic Polynomial Time.pdf
- Lesson 24- Reductions.pdf
- Lesson 25- Approximation
- When Lesson 25 is completed, this page becomes available.
- Lesson 26- Final Algorithmic Puzzles
- Lesson 27- The End
Full Video Playlist
The following contains all the videos used in the course, including several that are meant to be secret. If you don’t want spoilers, then you shouldn’t watch. But if you want to see how it all turns out, watch below! It’s 3 hours, 25 minutes total.
Contact Me
Thanks for checking out all my materials! I have chosen not to upload some of them, to prevent them from being abused by students searching for answers. This mostly includes instructor unit tests and grading scripts, answer keys, and reference answers. If you are an instructor interested in these materials, please feel free to fill out this google form: https://forms.gle/dU6U17Uy4QZ3KR577
If you would like to contact Dr. Bart directly, you can email him at acbart+atb@udel.edu